Scaling Test-Time Verification for Novel Materials
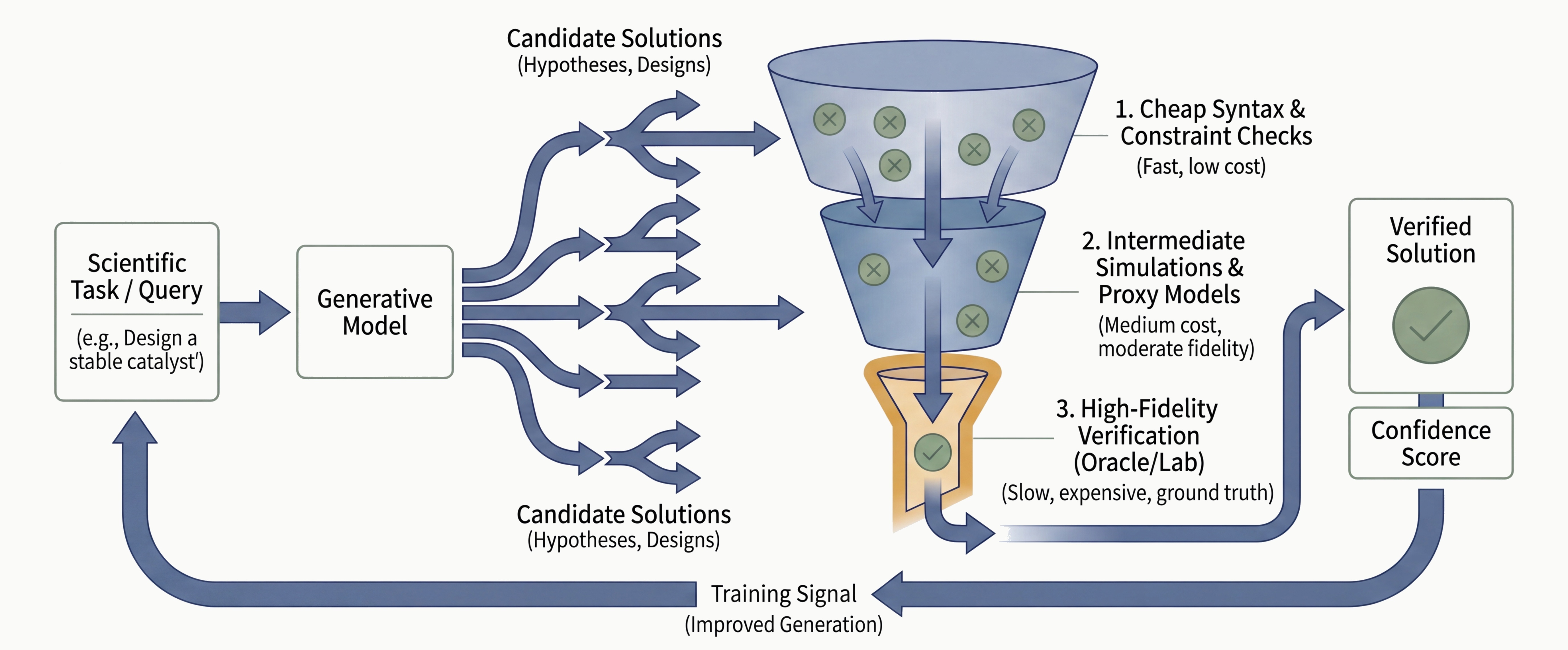
In language models, the generation-verification gap is a selection problem. The model generates correct answers but cannot identify which ones are correct. You close it by ensembling weak verifiers or scaling compute at test time. In materials discovery, the gap is harder. The final verifier is nature. You cannot ensemble a robotic physics lab. Neural surrogates1 return in seconds, physics simulations in minutes, but actual synthesis takes hours of irreducible physical time. Generate ten times more candidates and the verification burden grows ten times.
We set out to close that gap by pushing verification into the generation process itself. Crystal diffusion models already encode property information in their hidden states that they never use during sampling. A small timestep-conditioned probe MLP2 extracts this signal, and its gradient steers the generation trajectory toward target structures at test time. An unconditional model trained on 97.9% metals, with no property conditioning at all, reaches 24-43% of structures in a target band-gap window (the energy range that determines whether a material is a metal, semiconductor, or insulator), comparable to state-of-the-art conditional generation. Every candidate that exits the model has already been steered toward physical viability. The downstream pipeline starts from a higher-quality pool.
The candidate pool is no longer the constraint. Diffusion models like Crystalite (Hadži Veljković et al.) and MatterGen (Zeni et al.) propose novel candidates by jointly denoising atom identities, fractional coordinates (the position of each atom within the repeating unit cell), and lattice geometry from noise. Neural potentials screen for thermodynamic stability in seconds. Of over half a million candidates proposed by GNoME, fewer than one in five exhibited predicted synthesizability in subsequent analysis. The synthesis gap is where materials discovery stalls.
Multi-fidelity verification pipelines stack these layers, each adding confidence and cost. The question is where in this pipeline verification should start.
In our previous post, we described the judgment layer, training models to decide which evidence to trust, when to escalate to a more expensive verifier, and when to commit. That layer operates on candidates. If the candidates themselves are not pre-filtered for physical viability, the judgment system spends its budget evaluating structures that will never survive synthesis. Judgment decides what to pursue. Verification ensures what you generate can actually be built.
Self-Correcting Search
Self-correcting search (Hazra et al., Goodfire Research) exploits a gap between what diffusion models encode internally and what they express in their outputs. A probe trained on MatterGen's GemNet3 hidden states can predict what the band gap of the final structure will be at each intermediate denoising step. Self-correcting search uses this prediction as a feedback loop. At each step, the probe evaluates the proposal, and Metropolis-Adjusted Langevin Ascent4 accepts or rejects it based on whether it moves toward the target property range.
Standard conditional generation with MatterGen achieves 15% of samples in the target band-gap range, dropping to 6.5% when filtering for stable, unique, and novel candidates. Self-correcting search pushes forward the targeting-viability frontier at every conditioning strength tested, generating ~30% more viable candidates in the target range. The approach is general. Any property predictable from model internals becomes a viable steering signal.
We reproduced these results on a single GB10 GPU to understand the method's behavior across conditioning strengths and random seeds.
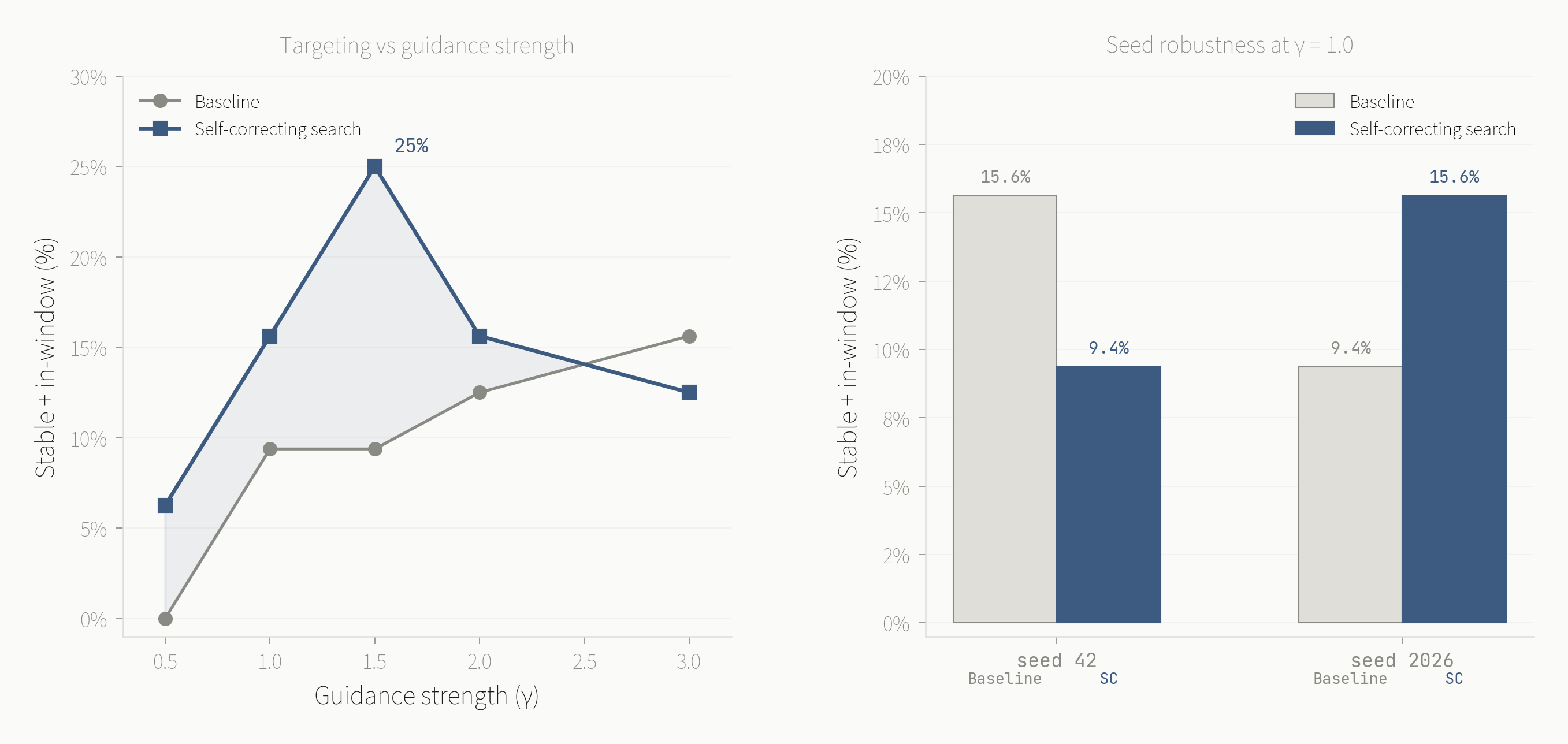
At gamma=1.5, self-correction produces 25-28% stable-and-in-window candidates, with 43% of relaxed structures in the target band-gap range. Structural viability improves from 54% to 70%. Self-correction improves both targeting and structural validity. Seed robustness varies at lower conditioning strengths, and the robustness variant (best-of-3 with a hard floor) stabilizes performance at the cost of peak throughput.
Model internals carry verification signal that meaningfully improves generation. This was the starting point for our work. The natural question was whether the same principle extends beyond conditional models. MatterGen receives the band-gap target as input at every conditioning strength. Can test-time verification steer a model that has no conditioning signal at all?
Probe-Gradient Guidance
Crystalite (Hadži Veljković et al.) is a ~67M-parameter Diffusion Transformer that generates crystal structures unconditionally. No property target enters the model. It denoises atom tokens, fractional coordinates, and lattice descriptors jointly from noise, using a subatomic tokenizer that encodes elements as continuous vectors derived from periodic table position and valence structure. Its training data is Alex-MP-20 (675,204 structures total, 540,162 in the training split), 97.9% of which are metals by our analysis. If the goal is generating wide-bandgap semiconductors, the base distribution has no coverage of the target region.
We trained a small timestep-conditioned two-layer probe MLP on Crystalite's atom-mean hidden states to predict band gap. The probe has 256 hidden units and 197,890 parameters in total. The probe achieves 0.957 AUROC.5 The model represents whether a structure is metallic or insulating at every denoising step, despite never being trained to condition on that property. Kreiman et al. show this is a general property of atomistic transformers. Given sufficient data, standard attention learns interatomic structure without hard-coded equivariance, encoding physics the model was never explicitly trained on.
We first applied the same Metropolis accept/reject strategy that works on MatterGen. On an unconditional model, it failed across all 36 configurations tested. Every one produced 0% in-window and 97-100% metals. Metropolis can only select among proposals the model already generates. If the base distribution is 97.9% metals, there are no insulator proposals to select. Passive verification requires base distribution coverage. Active steering creates it.
Instead of accepting or rejecting proposals, we backpropagate through the probe at each denoising step to produce a gradient on the generation trajectory. The gradient pushes the denoising path toward structures with higher predicted band gap.
At guidance weight zero, the model generates what it always generates. 96.5% metals, 0.0% in the target window. At w=1, metals drop to 0.8% and 3.5% of structures hit the 4-6 eV range. At w=10, metals reach 0.0% and 24.2% of structures hit the target, with a mean band gap of 4.19 eV. An unconditional model trained on 97.9% metals reaches comparable targeting accuracy to MatterGen's conditional generation with self-correcting search (25-28%), steered entirely at test time.
Head to Head
The comparison between MatterGen with self-correcting search and Crystalite with probe-gradient guidance is not a model-versus-model benchmark. The two systems differ in architecture (equivariant GNN6 vs. Diffusion Transformer), conditioning (conditional vs. unconditional), and verification mechanism (accept/reject vs. gradient steering). The juxtaposition tests how far the test-time verification principle generalizes.
| MatterGen + Self-Correction | Crystalite + Gradient | |
|---|---|---|
| Targeting (in-window) | 25-28% at gamma=1.5 | 24.2% (base) / 42.6% (balanced) |
| Latency | 9-16 min / 32 samples | ~5 sec / 10 samples |
| Structural validity | ~70% stable | 100% lattice, 99.6% geometry (balanced) |
| Conditional model | Required | Not required |
| Per-property retraining | Required | Swap probe (small probe MLP) |
| Compositional uniqueness | Not reported at scale | 99.7% (base) / 78% (balanced) |
| Seed robustness | Varies (9-16% at gamma=1.0) | Stable across 3 seeds |
| Formation energy probe | N/A | AUROC 0.990 |
MatterGen with self-correction achieves 25-28% stable-and-in-window at its strongest conditioning. Crystalite with probe-gradient guidance achieves 24.2% in-window on the base model, rising to 42.6% on a balanced-training checkpoint. Band-gap hit rates on relaxed structures converge at 43% for MatterGen (gamma=1.5) and 42.6% for the balanced Crystalite model (w=3).
Latency is the difference. Crystalite's base architecture is over 100x faster than MatterGen at generation (22 sec vs 2,639 sec per 1,000 structures). With guidance overhead, guided Crystalite remains over 50x faster per sample than MatterGen with self-correction. Sweeping across guidance weights, composing constraints, and regenerating takes seconds. Changing the target property means swapping a 256-parameter probe, not retraining the generator.
MatterGen's strength is structural maturity. Its equivariant GNN architecture produces physically valid crystal structures by construction. Crystalite's base model (trained on the full Alex-MP-20 distribution) achieves high compositional diversity (99.7% unique) but lower structural validity (5-16%). A balanced-training checkpoint resolves this, reaching 100% lattice validity and 99.6% geometry validity, at the cost of reduced diversity (78% unique). We return to this tradeoff below.
The same verification principle, applied through different mechanisms on different architectures, produces comparable targeting in both cases.
Stronger conditioning typically collapses the output distribution. We tested this directly.
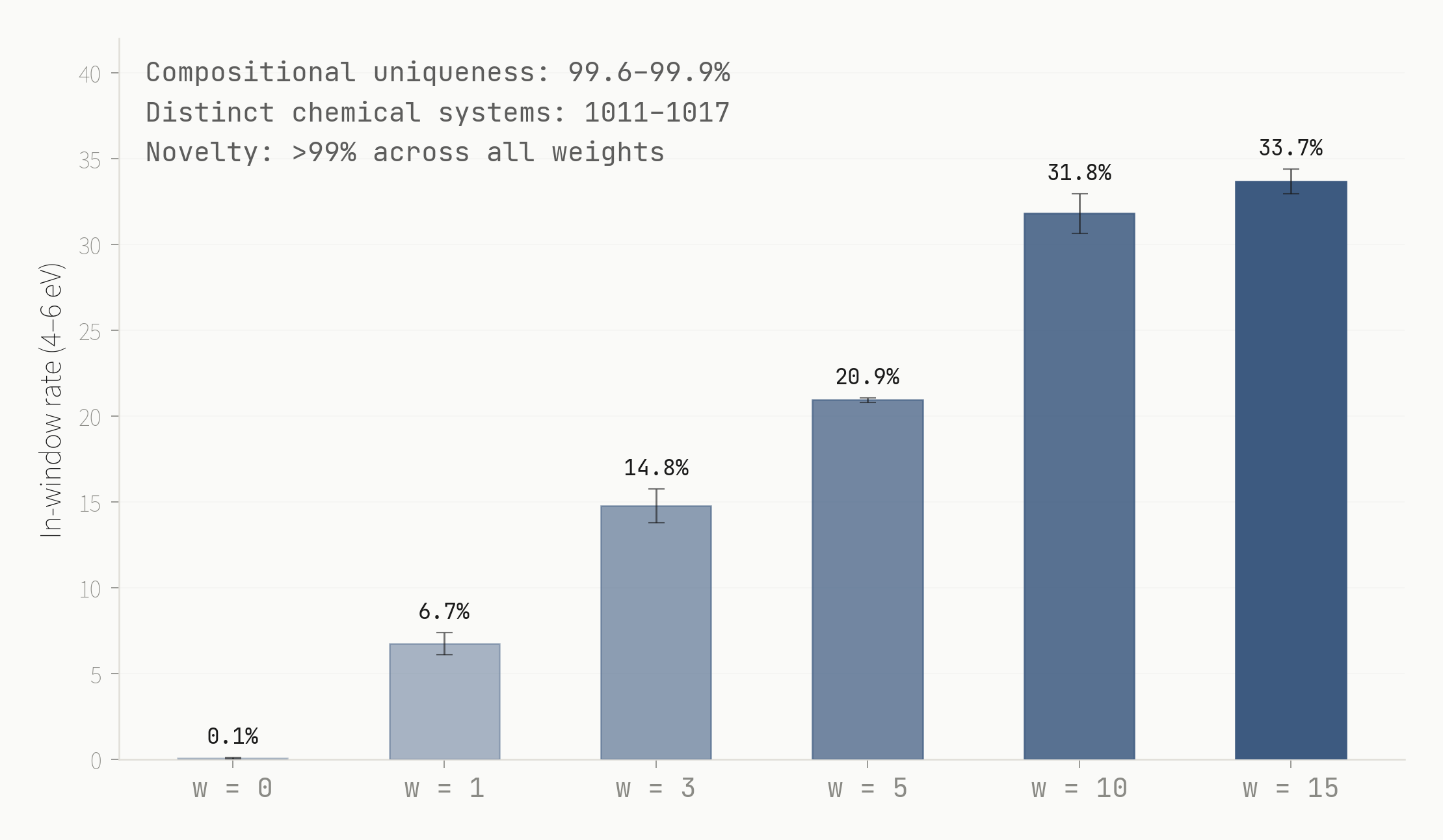
Every guidance weight Pareto-dominates the baseline. At w=10, in-window rate reaches 31.8% while compositional uniqueness holds at 99.7% and novelty stays above 99%. The probe gradient opens a different compositional region. The number of distinct chemical systems explored stays flat across all weights.
From Diversity to Production
The base model generates compositionally diverse candidates but not structurally valid ones for the target property range. Alex-MP-20 is 97.9% metals. A balanced training subset with 35% insulators fixes this. The balanced checkpoint at w=3 produces 42.6% in-window candidates with 100% lattice validity.
Not everything is reachable from model internals. An E_hull7 probe achieves 0.000 AUROC. E_hull measures how far a structure sits from the most stable known compounds in its chemical system. Structure-level properties are accessible. Database-relative metrics are not. Real queries also have multiple constraints, some continuous (band gap), some discrete (which elements to include or exclude). Probe-gradient steering handles the former. Token masking handles the latter.
Integrating Verification into Generation
Does the verification engine improve a conditional model that already has its own search procedure? We tested this on MatterGen with a fixed budget of 100 expensive validations per method. The three variants are self-correcting search alone, conditional generation with the engine replacing self-correction, and self-correcting search composed with the engine.
| Variant | Yield @0.15 eV | Yield @0.10 eV | |
|---|---|---|---|
| Self-correction | band_gap_only | 5 | 5 |
| Self-correction | band_gap_rohs | 5 | 5 |
| Conditional + engine | band_gap_only | 5.7 | 5.3 |
| Conditional + engine | band_gap_rohs | 4.7 | 4.3 |
| Self-correction + engine | band_gap_only | 10 | 9 |
| Self-correction + engine | band_gap_rohs | 9 | 9 |
Validated hits per 100 expensive evaluations on MatterGen. e_above_hull thresholds in eV. band_gap_only selects on predicted band gap; band_gap_rohs adds a rule-of-thumb hardness screen. Self-correction and self-correction + engine are single-seed; conditional + engine is averaged across three seeds.
Replacing self-correction with the engine alone produces mixed results, slight gains on one variant and slight regression on the other. Composing the engine with self-correction doubles validated yield. On the same candidate pool, with the same evaluation budget, the composed pipeline produces 10 validated hits per 100 evaluations versus 5 for self-correction alone. At the stricter threshold, 9 versus 5. The pattern holds across both selection variants.
The verification layer does not replace the generator or its search. It improves selection from what the model already produces, enabling twice the viable candidates.
The self-correction baseline and the composed pipeline are each single-seed comparisons. The engine-only variant has three seeds. The direction is consistent across both variants and both thresholds.
From Generation to Synthesis
Inference-time verification changes the scaling laws of the generation-verification gap. When verification improves both generation and selection under a fixed evaluation budget, the same experimental throughput produces more verified candidates.
The mechanism is composable. Stacking probes and token masks adds verification dimensions without retraining. The cost of adding a constraint is training a small probe MLP, not retraining the generator.
The probes cannot reach the property that matters most. Synthesizability depends on kinetics, processing conditions, and precursor chemistry. No model internal encodes it, because no training dataset contains it. The signal lives in experiment logs. What was attempted, what formed, what failed. If that signal were available as supervision, the same gradient mechanism would steer generation toward structures pre-filtered for physical realizability.
Judgment decides which evidence to trust and when to commit. Verification steers generation toward structures worth committing to. Better candidates produce more informative experiments. More informative experiments produce the synthesis outcome data that the next generation of verification probes needs. The verification signal that matters most is the one that comes back from the lab.
Citation
@article{barnes2026verification,
author = {Barnes, Jarrod},
title = {Scaling Test-Time Verification for Novel Materials},
journal = {Dynamical Systems},
year = {2026},
url = {https://dynamicalsystems.ai/blog/scaling-test-time-verification}
}If you are running autonomous experiments, building generation-to-synthesis pipelines, or working on synthesizability prediction, we want to hear about it.