The Control Plane for Physical R&D
Physical R&D is becoming programmable. Models can now generate hypotheses, candidates, protocols, simulations, and analyses faster than teams can manually verify them. The same shift that changed software is beginning to reach science. When generation gets cheap, the bottleneck moves to review, validation, and trusted execution.
That bottleneck is expensive in the physical world. AM qualification, battery process validation, aerospace materials programs, and external test-lab workflows span shared instruments, suppliers, standards bodies, reviewers, and destructive physical tests. The scarce resource is not more candidates. It is trusted physical evidence. What to test, when to test it, what would change the decision, and how the path can be replayed.
In our earlier work on training scientific judgment, we described this as the planner-verifier boundary. It is the decision layer where an agent must allocate search, trust evidence, escalate verification, and revise belief under budget. Reactor is the product version of that thesis for physical R&D campaigns.
This case study tests whether campaign control can compress branch selection before physical spend.
Three layers are emerging. Frontier models form the reasoning layer. They propose, analyze, plan, and write rationale. Labs, foundries, simulators, instruments, and human operators form the execution layer. Between them sits the control plane for campaign intent, evidence gates, branch decisions, budgets, provenance, replay, and memory.

That is the role Reactor is built to play. It makes physical-world learning compound like software.
Reactor is Dynamical's agentic workbench for physical R&D. It turns a messy validation objective into an auditable campaign. It proposes candidates, routes literature, simulation, and verifier work, allocates scarce physical-test budget, ingests results, records decisions, and preserves the evidence trail for review. Reactor decides what deserves the next expensive test and why.
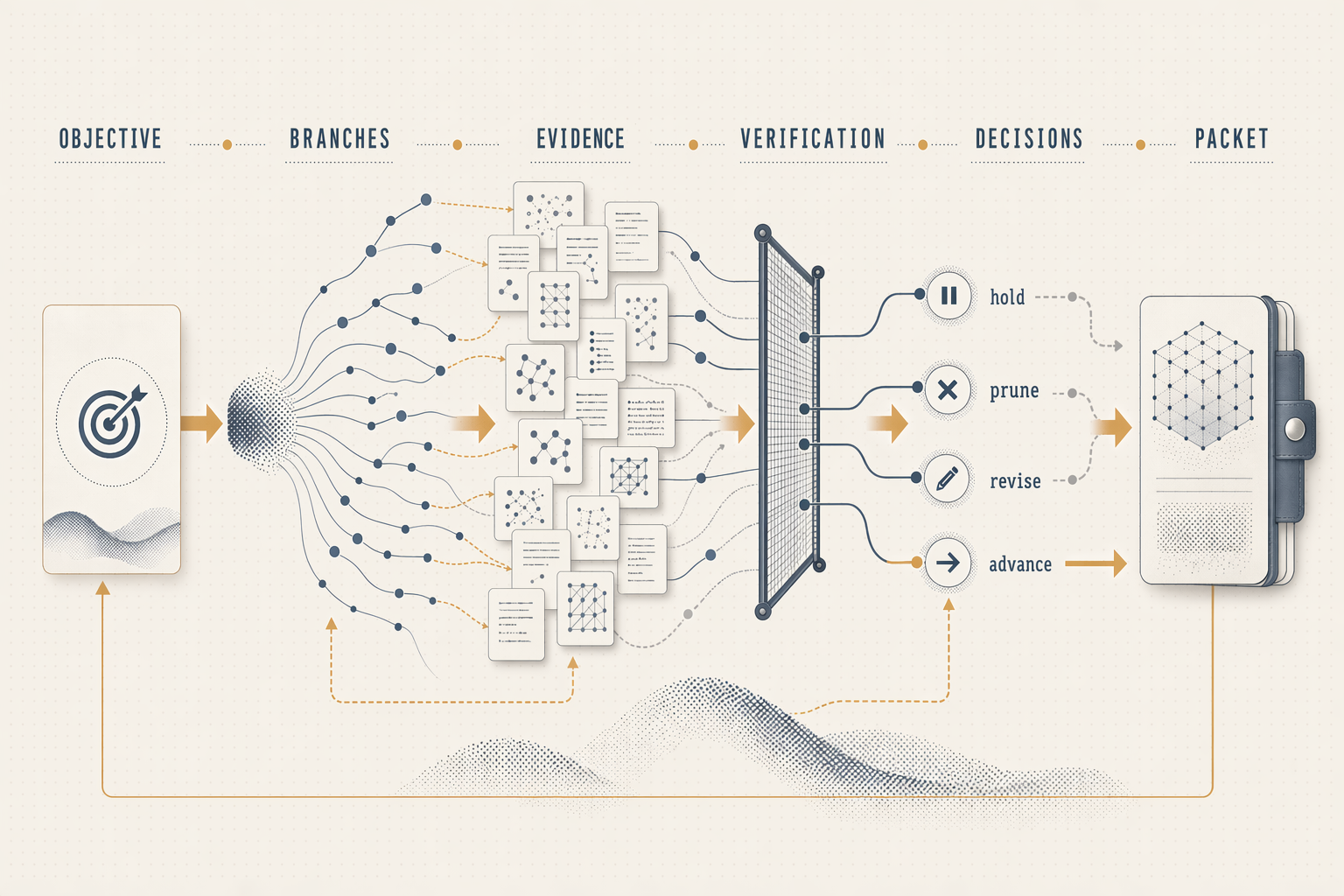
We put Reactor on a public US Navy SBIR AM automation objective, framed as a pre-qualification campaign, to see what an auditable campaign packet looks like in practice. What candidates were considered, what evidence was trusted or rejected, what physical-test budget was spent. And what should be tested next. The run produced a coupon-ready test plan in under 15 minutes: one process window selected after 30 branches and proposal baselines were considered, three coupons to build, explicit pass/fail thresholds on density, defects, microstructure, and tensile strength, and a named fallback if the lead fails. The full decision trail is preserved for review.
Inside Reactor
Reactor separates campaign work into two public concepts, the orchestrator and the ledger.
The orchestrator is the active side of the system. It interprets the objective, searches literature, calls tools, launches simulation and verifier jobs, coordinates subagents, and proposes candidate branches. Its job is to widen the campaign, gather context, explore options, and generate plausible next moves.
The ledger is the truth side of the system. It records admitted evidence, candidate state, budgeted physical-test spend, explicit decisions, and the packet that moves to physical validation. Its job is to narrow the campaign, decide what is trusted, what is pruned, what is revised, and what advances.
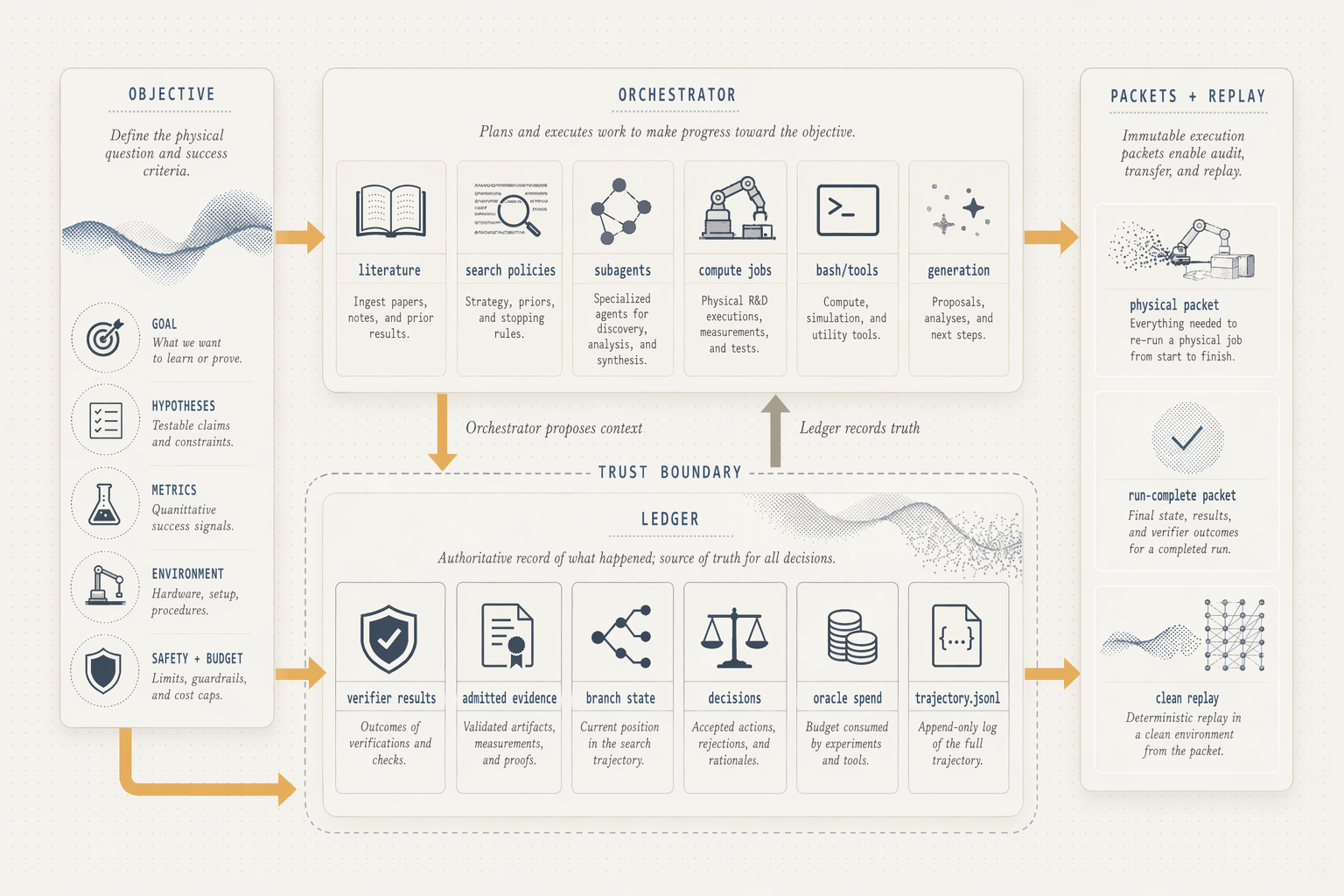
A recent analysis of LLM-based scientific agents found that evidence gets ignored in 68% of traces and refutation-driven belief revision occurs in only 26%. Scientific agents do not become trustworthy just by having access to tools. Reactor treats this as a system-design problem. Autonomous work can propose context, but only admitted, verified, evidence-backed results can change the campaign record.
In the NV030 run, that boundary produced a replayable trail of candidate branches, verifier results, literature claim cards, an explicit oracle reveal, branch decisions, a physical-validation packet, and clean replay. The orchestrator widened the search. The ledger made the decision path durable.
Automating Additive Manufacturing
Pre-qualifying an additive-manufacturing process window is a combinatorial physical-validation campaign. Each new material, machine, power setting, scan strategy, and post-processing recipe creates another process window that may need physical validation. The space is large. The tests are slow and expensive. The evidence behind each decision is scattered across papers, simulations, supplier reports, prior coupon runs, and expert judgment. Most candidate windows never get tested.
The public US Navy AM automation objective names the bottleneck directly. Connect material, machine, geometry, process parameters, defects, post-processing, and performance targets to the next physical validation step. For Reactor, the point is not generic materials discovery. It is campaign control. Decide which process branch deserves coupon spend, what evidence supports that decision, and what uncertainty the coupon must resolve.
Reactor ran an internal public-surrogate campaign on IN718 laser powder bed fusion, using NIST AM-Bench public benchmark data as physical context. The goal was to increase pre-qualification throughput by compressing a large candidate space into one coupon-ready test plan, preserving the evidence behind the choice, and leaving a replayable decision trail for the next round.
We put Reactor to the test across other physical-validation workflows, ranging from hot-corrosion coating downselects to high-strength-steel surface-treatment planning. Those traces exercised the same orchestrator and ledger boundary. They are breadth evidence for Reactor's campaign-control pattern, while the additive-manufacturing campaign makes the product concrete.
The emitted packet recommended an IN718 LPBF process window at 245 W, 800 mm/s, 100 micrometer hatch, 40 micrometer layer, 67 degree rotating scan, followed by HIP, solution treatment, and aging.
The plan called for three coupons at those parameters, each measured for density, internal defects, grain anisotropy, tensile strength, and residual stress. Advance if every threshold passes. Otherwise revise, or fall back to the alternate lead candidate.
| Packet field | Value |
|---|---|
| Lead window | 245 W, 800 mm/s, 100 micrometer hatch, 40 micrometer layer |
| Build plan | 3 coupons |
| Advance criteria | Density, defects, microstructure, tensile strength, residual stress |
| Failure path | Revise or fall back to alternate lead |
Result
The result was decision compression before physical spend. Reactor did not win by generating the largest candidate pile. It made a physical-validation campaign inspectable. Many plausible branches went in. One packet came out with an evidence boundary, pass/fail thresholds, a fallback branch, and a replay trail.
The run kept its limits visible. Literature support was thin in places. One search-policy comparator degraded and was labeled as proposal-only, not evidence. The public benchmark reveal reaffirmed the lead branch rather than overturning it. Those gaps did not disappear. They became the reason for the coupon packet.
Toward Programmable Science
Making science programmable does not mean replacing physical reality with model output. It means turning every objective, candidate, verifier result, decision, packet, and physical result into reusable campaign memory. As models generate more hypotheses and candidates than any team can physically test, the scarce resource becomes disciplined validation.
Reactor is the control plane for that loop. It keeps the campaign owner oriented around what should be tested next, why that branch deserves physical spend, and what evidence would change the decision.
That is how physical-world learning starts to compound like software.
If you own an expensive physical-validation workflow and the bottleneck is deciding what deserves the next test, we want to hear about it.